While similarly post-apocalyptic and “numbers-driven,” this post is not actually about a new NetFlix series. Rather, the main character of the story is HaluEval, a new “standard benchmark” for measuring whether a large language model is hallucinating — producing fluent, plausible-sounding text where it ought to be reporting a fact. The benchmark contains around 35,000 examples, each labeled as a hallucination or not. Researchers run their model against it; the resulting accuracy number ends up in papers, on leaderboards, and in vendor pitches.
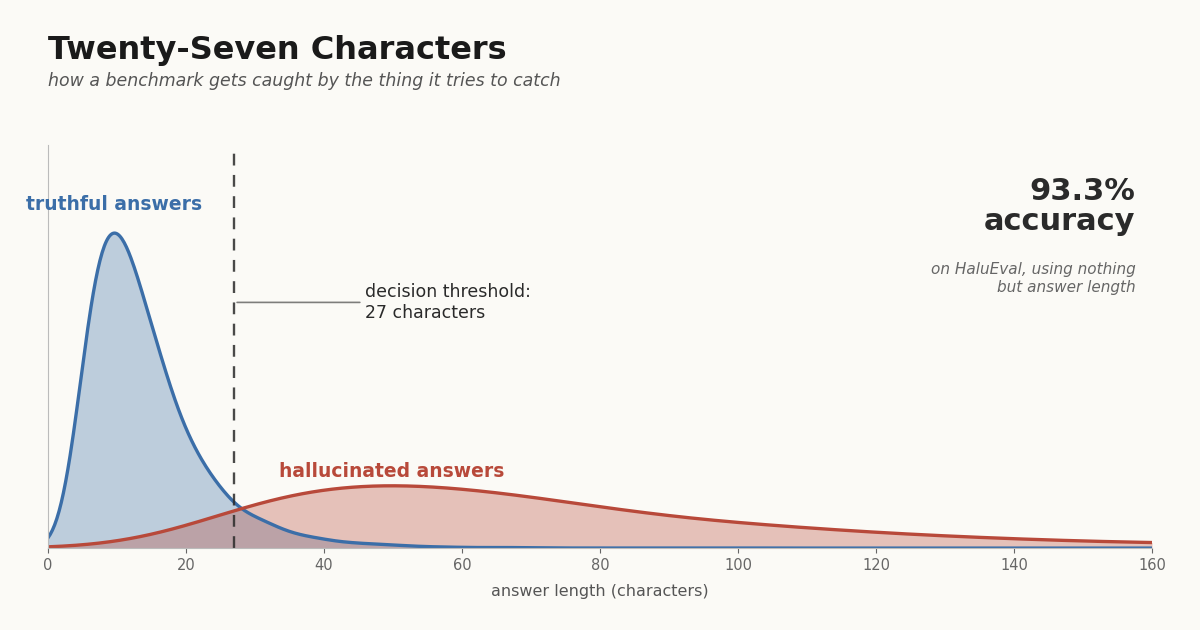
A recent analysis points out that you can score 93.3% on HaluEval by ignoring the model entirely and flagging any answer over 27 characters as a hallucination. A neighboring benchmark, TruthfulQA, falls to the same kind of trick — picking the shorter of the offered candidate answers nets 65% accuracy against a 50% random baseline. The trivial classifier beats the careful one.
This is funny on its surface and, I think, much funnier underneath. The funny-underneath part is that a benchmark for classifiers is itself a classifier, and the benchmark just got caught doing exactly the thing it was built to catch the models doing.
A Classifier All the Way Down
To measure hallucination you need a labeled dataset: outputs paired with verdicts, hallucination or not. The world does not come pre-annotated, so somebody has to construct one. The HaluEval team did what is standard — they used an LLM to generate plausible-but-false answers alongside truthful ones, then had human annotators confirm the labels. The verdicts are not facts about the world. They are facts about the dataset-construction pipeline.
That distinction matters because every dataset-construction pipeline leaves a fingerprint. Asking a model to fabricate a plausible answer produces, on average, longer outputs than the truthful answers drawn from elsewhere. The made-up answers have to do more work — supplying the entities, dates, and connective tissue that a true answer can leave implicit. Length is not measuring fabrication. Length is measuring which side of the pipeline an answer came from. (Twenty-seven characters, John. Your average sentence breaks a hundred.)
Descriptive or Constitutive
We have been here before. (All measurements are local.) HaluEval is not describing hallucination as it exists in the wild. It is constituting a particular operational meaning of “hallucination” — the one its pipeline produces. Models that “do well on HaluEval” are doing well on that constituted thing, not on the underlying phenomenon the benchmark was built to address. The distinction is invisible until somebody points out that 27 characters is doing all the work.
This is not a complaint about HaluEval’s authors, who did the unglamorous, necessary work of building a benchmark in a field that needed one. It is the standing point that what gets measured is constituted by the act of measurement, and the constitutive choices can be exploited by anything attentive enough to notice — including, awkwardly, a one-line check on string length.
Same Game, New Rules
The fix is obvious: rebalance the dataset so length isn’t a tell. Once that’s done, something else will be a tell — lexical diversity, average token probability, frequency of hedging words, pick your favorite latent feature. The pipeline leaves some fingerprint, and any classifier with enough degrees of freedom will find it. Closing one loophole opens another, which is what I mean when I drag out the phrase conservation of impossibility: a fix that does not change the underlying structure relocates the failure rather than resolving it. The gameability of HaluEval is a property of the gap between “the thing we want to measure” and “the thing the dataset lets us check,” and that gap is not closed by patching a feature. This is, more or less, the song we keep getting backwards: optimize against the proxy and call it progress on the target.
Maggie and I have a related point in our AJPS paper on classifiers and feedback — once the population subject to classification can respond to the classifier, accuracy-maximizing rules can do things that look outright Bayesian-perverse, like classifying positive precisely when the signal is weakest. HaluEval is not that result, but it lives in the same neighborhood. A signal that looks like noise — length, of all things — can carry most of the discriminating information once you know how the population was constructed. The twist is that here, the population is the dataset, and the construction is the experimenter’s.
Who Watches the Watcher
A benchmark exists because we wanted a third-party arbiter — somebody whose verdicts about model outputs are supposed to be more trustworthy than the model’s verdicts about its own. But the arbiter has, structurally, the same epistemic problem as the thing it is arbitrating. It produces verdicts; the verdicts depend on a construction; the construction has fingerprints; the fingerprints can be detected by anyone who looks; and once detected, they can be optimized against.
That isn’t a counsel of despair. It’s a counsel of humility, which is most of what I have to offer on most topics. The benchmark is useful. The leaderboard tells you something. It just doesn’t tell you quite what it looks like it’s telling you, and the gap between those two things is exactly where careful work has to live.
With that, I leave you with this.
1 thought on “Twenty-Seven Characters”
Comments are closed.