
The Republican Party is in crisis. This year’s presidential campaign is arguably evidence enough for this conclusion, but it is important to remember that there are really (at least) two “Republican Parties”: one composed of voters and another composed of Members of Congress.
A split in the broader GOP is troublesome for Republican elites because, among other things, it complicates the quest for the White House, which might also cause significant problems for Republican Members seeking reelection. But splits in the broader party do not necessarily affect governing. A split in the “party in Congress,” however, can greatly complicate governing. Indeed, one might argue that the beginnings of such a split caused the downfall of former Speaker Boehner, the government shutdown of 2013, and the near-shutdown of 2015.
As Keith Poole eloquently notes, the potential split in the GOP appears eerily similar to the collapse of the Whig Party in the early 1850s (the last time a major party split occurred in the United States). A key difference between the current Congress and those in the 1850s is the lack of a “second dimension” of roll call voting. Without going into the weeds too much, what this means is that there is no systematic splitting of the Republican party on a repeatedly revisited issue. In the 1850s, that issue was slavery (specifically how it would be dealt with as the nation admitted new states).
Because of this, our roll call-based estimates of Members’ ideologies essentially place all members on a single, left-right dimension. This implies that, for most contested roll call votes, most of the Republicans vote one way and most of the Democrats vote the other. The figure below, which displays the proportion of roll call votes in each Congress and chamber that pitted a majority of one party against a majority of the other, illustrates how this has become increasingly the case.

Of note in the figure are two things. The first is the overall increase in party line voting since the civil rights era. Party line voting was rare during this era in part because the Republican party controlled relatively few seats in either chamber and, relatedly, because the Democratic party often split on civil rights legislation, with Southern Democrats relatively frequently voting with Republicans. As the South “realigned,” beginning in earnest with the 1980 election, the parties became more clearly sorted and party line voting became more common: with civil rights legislation largely off the table, fewer and fewer votes split either party.
The second thing to note is that party line voting dropped precipitously in 1997 (the first Congress of Bill Clinton’s second term), rose during George W Bush’s presidency, and unevenly surged during Obama’s first 3 Congresses. Thus, “partisan voting” is definitely not on the decline in recent years. This is important for many reasons, but for our purposes it is important because it implies that the nature of “partisan warfare” has not qualitatively changed in terms of the structure of roll call voting, writ large.
Unpredictability and Ideology
Given a Member’s estimated ideology (“ideal point”), we can predict how that member should have voted on each roll call vote. (I am omitting some details.) Using this and the actual votes, we can calculate how many times each Member’s vote was “mispredicted” by the estimated ideal point.
In a nutshell, these are situations in which most of the other Members who have similar ideological voting records voted (say) “Yea,” members on the other side of the ideological spectrum voted “Nay” and the member in question voted “Nay.” For example, if all of the Democrats voted “Nay” on some roll call, and all of the Republicans other than Ted Cruz voted Yea, then Senator Cruz’s vote would be mispredicted by Cruz’s estimated ideal point (which is the most conservative among the current Senate).
Typically, this misprediction, or “error” rate is higher for Members who are (estimated to be) ideological moderates. This is for several reasons. First, if a member is simply voting randomly, then he or she would be estimated to be a moderate. Second, and more substantively, if a member is actually moderate, then his or her vote is more likely to be determined by non-ideological factors because his or her ideological preferences are relatively weaker than for someone who is ideologically extreme.
In any event, the figures below illustrate the House and Senate for a “typical” recent Congress, the 109th Congress (2005-6). In the 109th both chambers of Congress were controlled by the Republican Party, following the reelection of George W. Bush. In both figures, the horizontal axis is the estimated ideology so dots on the left represent liberals and dots on the right represent conservative), and the vertical axis is the proportion of votes cast by that member that were mispredicted by his or her estimated ideology. Each figure includes an estimated quadratic equation for “expected error rate.”[1]
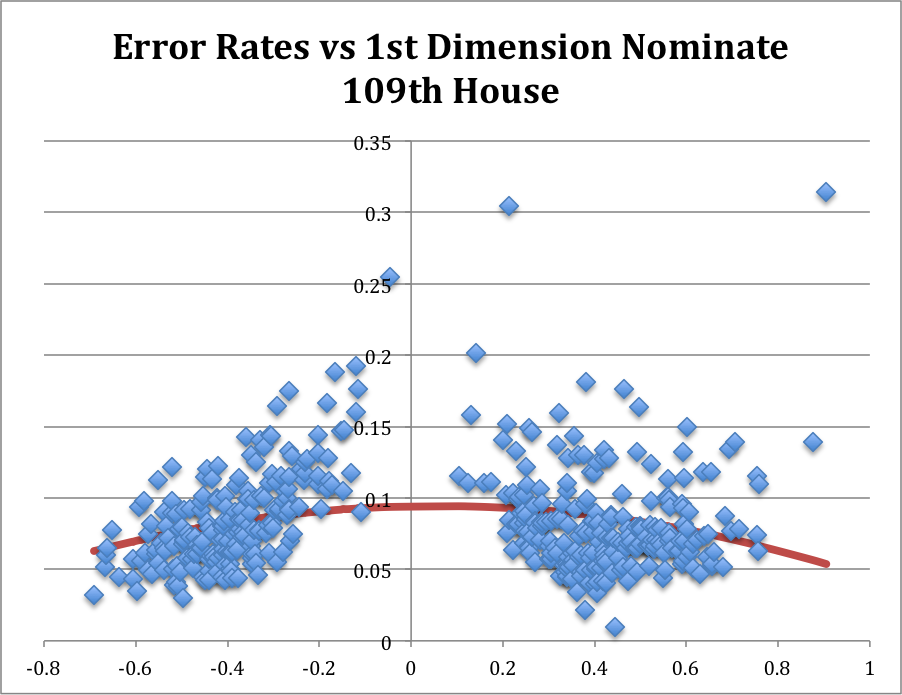
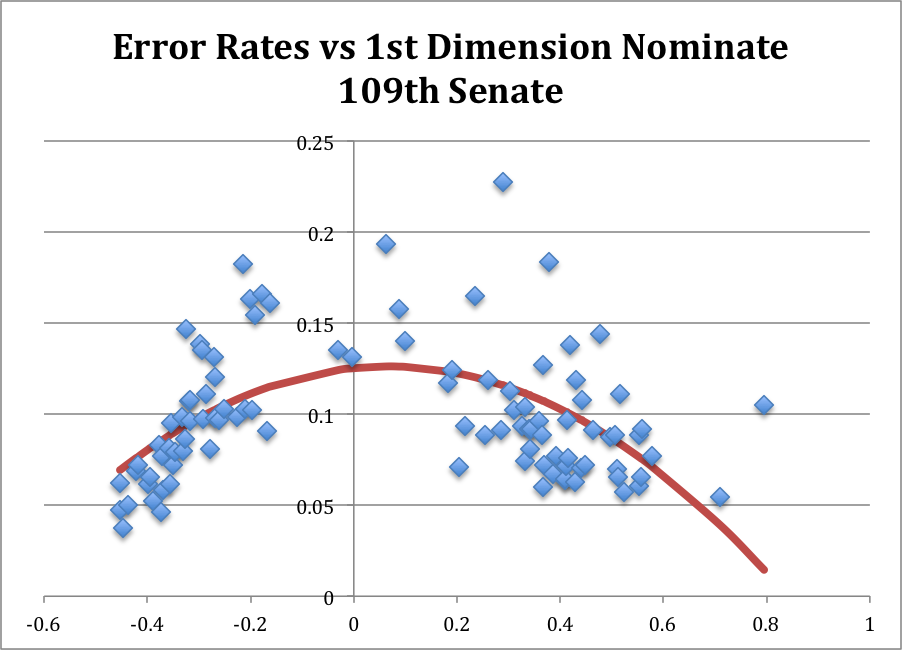
In both figures, with one notable exception in the 109th House (Ron Paul (R, TX), Senator Rand Paul’s father), bear out the general tendency for moderates to have higher error rates than “strong” liberals and conservatives. [2]
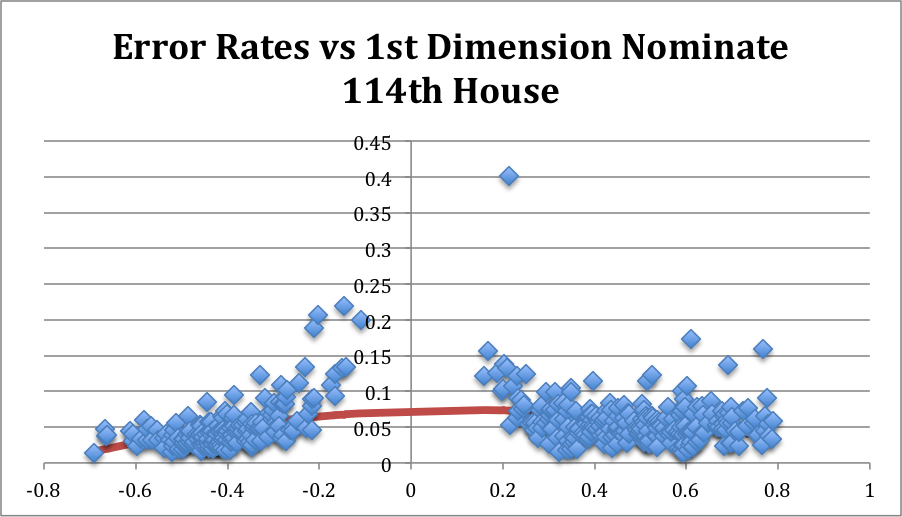
What About Today? Let’s turn to the 114th Congress (through March 2016). Looking first at the House, the pattern from the 109th is still present.[3] Moderates are characterized by higher error rates than strong liberals or conservatives.
 In the 114th Senate (through March 2016), however, the picture is qualitatively and statistically different:
In the 114th Senate (through March 2016), however, the picture is qualitatively and statistically different:
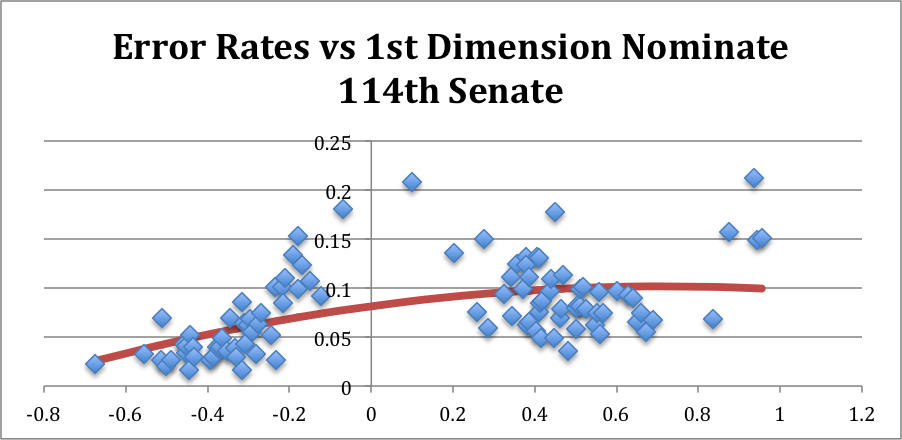 In particular, the Republican party has generally higher error rates than does the Democratic party.[5] This indicates that Republican Senators have been more likely to vote against their party than have been Democratic Senators or, more substantively, the internal ideological structure of the Republican party in the Senate has played a smaller role in determining how GOP Senators have voted in this Congress.
In particular, the Republican party has generally higher error rates than does the Democratic party.[5] This indicates that Republican Senators have been more likely to vote against their party than have been Democratic Senators or, more substantively, the internal ideological structure of the Republican party in the Senate has played a smaller role in determining how GOP Senators have voted in this Congress.
Who’s Being Unpredictable?
Consider the list of the 15 Senators with the highest error rates:
| Name | State | Error Rate | Party | Conservative Rank |
| PAUL | Kentucky | 21.2% | GOP | 3rd |
| COLLINS | Maine | 20.8% | GOP | 54th |
| MANCHIN | West Virginia | 18.1% | Dem | 55th |
| HELLER | Nevada | 17.7% | GOP | 29th |
| FLAKE | Arizona | 15.7% | GOP | 4th |
| KING | Maine | 15.3% | Independent | 60th |
| CRUZ | Texas | 15.1% | GOP | 1st |
| KIRK | Illinois | 15.0% | GOP | 51st |
| LEE | Utah | 14.9% | GOP | 2nd |
| MURKOWSKI | Alaska | 13.6% | GOP | 53rd |
| NELSON | Florida | 13.4% | Dem | 61st |
| PORTMAN | Ohio | 13.2% | GOP | 44th |
| MORAN | Kansas | 13.1% | GOP | 38th |
| MCCONNELL | Kentucky | 13.0% | GOP | 37th |
| AYOTTE | New Hampshire | 12.4% | GOP | 46th |
| HEITKAMP | North Dakota | 12.4% | Dem | 58th |
| MCCAIN | Arizona | 12.4% | GOP | 43rd |
| GARDNER | Colorado | 11.3% | GOP | 26th |
| GRASSLEY | Iowa | 11.1% | GOP | 48th |
| CORKER | Tennessee | 11.1% | GOP | 41st |
Tellingly, the four most conservative Senators have incredibly high error rates (and two of these (Paul and Cruz) made serious runs for the GOP presidential nomination). The rest of the list is dominated by Republicans. The four non-GOP Senators are in fairly conservative states (with Maine being an unusual case).[6]
Hindsight and looking back… I don’t have time to get into the weeds even more with this at this moment. For now, I just wanted to point out that voting in the current Senate is unusual: Republicans are breaking with their party more often than are Democrats, and a handful of “extreme” conservatives are breaking with the party at incredibly (indeed, historically) high rates. To quickly see the recent past, consider the 113th Congress:
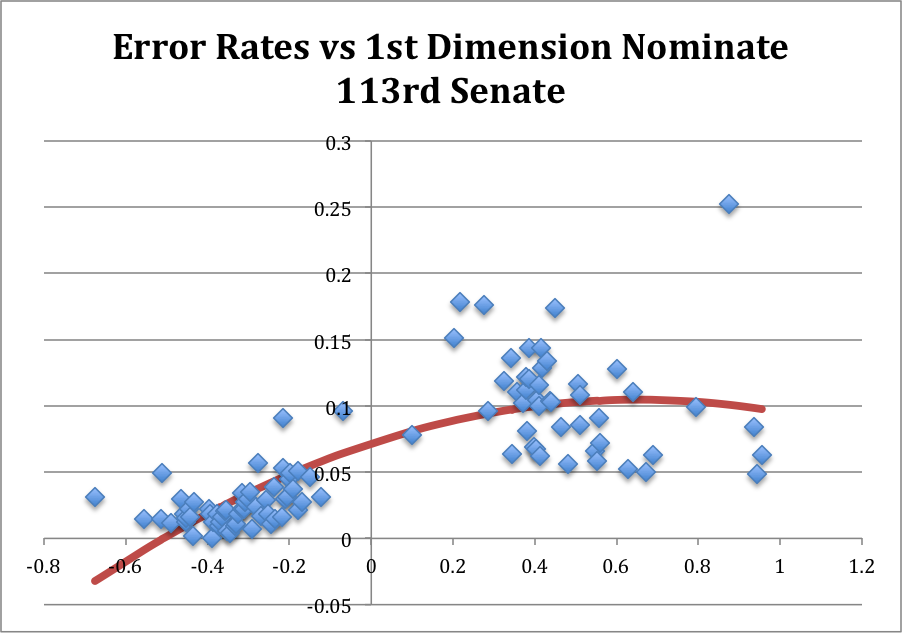
In the last Congress, Republicans were already breaking with their party at qualitatively higher rates than were their Democratic counterparts, but there was no real analogue to the cluster of 4 extremely conservative Senators who have been mispredicted so strongly in the 114th Congress. One of those 4—Senator Flake (R, AZ) was a newly-arrived freshman Senator in the 113th Congress and has continued to be difficult to predict in his second Congress.
What does it mean?
In line with both Keith Poole’s conclusion that the GOP shows significant signs of breaking up and the recent revolt among the GOP members in the House (where agenda setting is much more tightly centralized), I think what is happening is that (some of) the “estimated as conservative” wing of the GOP in the Senate is increasingly breaking party lines in pursuit of issues that are not being addressed by the chamber. Qualitative examples of such behavior are seen in the recurrent obstructionism among the “Tea Party wing” of the Republican party. (For example, see my theoretical work on this type of behavior and its electoral origins.) This rhetoric has also flared in the race for (both parties’) presidential nominations.
In line with this, of course, is the fact that the GOP has a disproportionately large number of Senators up for reelection in 2016. I haven’t had time to go through and compare the list of highly mispredicted Senators (please feel free to do so and email me about it!), but my hunch is that a bunch of “in-cycle” Senators are on that list.
For now, though, I leave you with this and this.
________________
[1] The quadratic term is significant (and obviously negative) in both chambers, as typical.
[2] The other Members with similarly high error rates in the House are Gene Taylor (D, MS), who would go on to be defeated 4 years later in the 2010 election, and Walter Jones (R, NC), who will show up again below: both were considered “mavericks” and were, as a result, estimated as being relatively moderate in ideological terms. In the Senate, the three highest error rates were (in order) Senator Mike DeWine (R, OH), who would be defeated in the 2006 midterm election by Sherrod Brown, Senator Arlen Specter (R, PA), a moderate Republican, and Senator John McCain (R, AZ).
[3] The quadratic term for the estimation of the relationship between estimated ideal point and error rate is again significant and of course negative.
[4] The quadratic term in this case is still negative, but no longer statistically significant. The linear term is positive, of course, and statistically significant.
[5] As is common in recent Congresses, there is no overlap between the parties’ ideological estimates so far this Congress: Senator Joe Manchin (D, WV) is the most conservative Democratic Senator, and Senator Susan Collins (R, ME) is the most liberal Republican Senator, but Senator Collins is estimated as being more conservative than Senator Manchin.
[6] Mitch McConnell is on this list for procedural reasons: he frequently votes “with” the Democrats on cloture motions when it is clear that cloture will fail, so as to reserve the right to motion to reconsider the vote in the future.
 total votes, and a candidate “controls”
total votes, and a candidate “controls”  of those votes, the Banzhaf index measures the probability, given the distribution of the other
of those votes, the Banzhaf index measures the probability, given the distribution of the other  votes across the other candidates, that the candidate in question will cast the decisive vote: that is, that he or she will have enough votes to pick the winner, given every way the other candidates could cast their ballots. (I’m skipping some details here. For the interested, the most important detail is that the index presumes that the other candidates will randomly choose how to vote.)
votes across the other candidates, that the candidate in question will cast the decisive vote: that is, that he or she will have enough votes to pick the winner, given every way the other candidates could cast their ballots. (I’m skipping some details here. For the interested, the most important detail is that the index presumes that the other candidates will randomly choose how to vote.) . For example, if a candidate has over half of the votes,[1] then that candidate’s Banzhaf index is equal to 1 (and those of all other candidates are equal to zero, and we’ll see that come up again below), because that candidate will always cast the decisive vote.
. For example, if a candidate has over half of the votes,[1] then that candidate’s Banzhaf index is equal to 1 (and those of all other candidates are equal to zero, and we’ll see that come up again below), because that candidate will always cast the decisive vote.
 .
.
 .
.
 ,
, is the number of people in group g in city C and $latex Pop^C$ is the total population of city C. Higher levels of CDI reflect more even populations across the different groups.[2]
is the number of people in group g in city C and $latex Pop^C$ is the total population of city C. Higher levels of CDI reflect more even populations across the different groups.[2] denote the number of people in group g in neighborhood n, and let
denote the number of people in group g in neighborhood n, and let  denote the total population in neighborhood n. Then city C’s
denote the total population in neighborhood n. Then city C’s  .
.
 ,
, and
and  . The result of one run is pictured below.
. The result of one run is pictured below.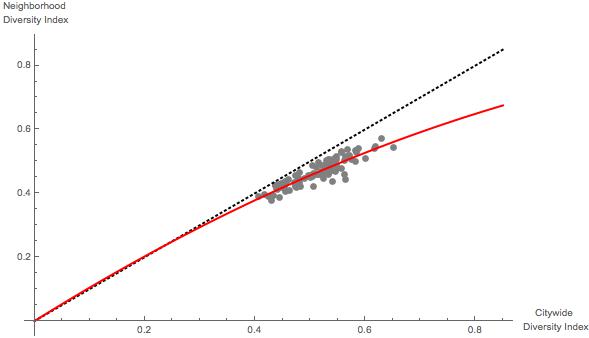
 . Thus, this measure is problematic to use when comparing cities that have measured “groups” in different ways.
. Thus, this measure is problematic to use when comparing cities that have measured “groups” in different ways. .
.