This Op-Ed in Forbes, “Almost Everything You Have Been Told About The Minimum Wage Is False,” by Jeffrey Dorfman, argues that increasing the federal minimum wage (1) would not affect as many people as you might think and (2) would not help the working poor as much as (say) teenagers.
The first half of Dorfman’s Op-Ed is misleading in important and ironic ways.[1] I will detail three significant logical failures in it, and then provide a more transparent accounting of how many people’s wages would be directly increased by an increase of the federal minimum wage to $10.10/hr.
Three Failures. First, Dorfman either misunderstands or misrepresents the difference between necessary and sufficient conditions when he writes:
First, people should acknowledge that this rather heated policy discussion is over a very small group of people. According to the Bureau of Labor Statistics there are about 3.6 million workers at or below the minimum wage (you can be below legally under certain conditions).
Dorfman should acknowledge that raising the federal minimum wage would affect not only those who earn a wage less than or equal to the current minimum wage. The data that Dorfman is discussing excludes anybody who receives $7.26/hr or more. Thus, Dorfman should acknowledge that the “small” group of 3.6 million people he is considering compose the relevant basis of discussion if we are considering a one cent increase in the federal minimum wage.[2]
Second, Dorfman starts comparing apples and oranges, writing
Within that tiny group, most of these workers are not poor and are not trying to support a family on only their earnings. In fact, according to a recent study, 63 percent of workers who earn less than $9.50 per hour (well over the minimum wage of $7.25) are the second or third earner in their family and 43 percent of these workers live in households that earn over $50,000 per year.
This is apples to oranges because the data in the (linked) study is from 2003-2007, before the Great Recession, but the BLS data is from 2012. Furthermore, Dorfman doesn’t take the time to actually report what the study does say (on page 593):
Of those who will gain, 63.2% are second or third earners living in households with incomes twice the poverty line, and 42.3% live in households with incomes three times the poverty line, well above $50,233, the income of the median household in 2007.
Let’s think about this for a second: ~20% of those who made less than $9.50/hr in 2007 lived in a household with an annual income (it turns out) of somewhere between $41,300 and $61,950. I mean, seriously, helping this kind of household—you know, hard-working and distinctly middle class—that would be a ridiculous outcome.
In addition, I’m going to be quick about Dorfman’s faulty (and, I think, disingenuous) logic in his implication that people poorly paid job “… are not trying to support a family on only their earnings” just because others in the household are working, too.
Namely, if you are the second or third earner in a family, that does not imply that you don’t need the money. In fact, I am going to blatantly assert that it’s probably the case that the number of “voluntarily non-working” 16+ year-olds in an American household is positively correlated with the household’s income. After all, many people work a job for, you know, the money. But, of course, some people might take near-minimum-wage jobs just to keep themselves busy.
Next, Dorfman starts making descriptive statements out of the blue:
...Thus, minimum wage earners are not a uniformly poor and struggling group; many are teenagers from middle class families and many more are sharing the burden of providing for their families, not carrying the load all by themselves.
The closest thing Dorfman putatively offers as evidence for the conclusion that these are teenagers (there is no evidence from what kind of families these teenagers come in the BLS data) is the BLS data, which again is constrained only to those earning no more than the minimum wage of $7.25/hr.
Finally, Dorfman says
This group of workers is also shrinking. In 1980, 15 percent of hourly workers earned the minimum wage. Today that share is down to only 4.7 percent. Further, almost two-thirds of today’s minimum wage workers are in the service industry and nearly half work in food service.
But again, the point is that raising the minimum wage to (say) $10.10/hr, as President Obama has called for, would help more than only those who earn the minimum wage.
I’m not just going to point out Dorfman’s mistakes. I have done a little digging (it took me about 15 minutes, to be clear, to get real numbers), and I’ll give a better estimate of how big that “very small group of people” really is.[3]
The Occupational Employment Statistics Query System, provided by the U.S. Bureau of Labor Statistics, provides a different picture of how many people would be impacted by a change in the federal minimum wage to $10.10/hr.
The most recent data, from May 2012, is displayed at the end of this post. The points I’d like to quickly point out are as follows:
- In Food Preparation and Serving Related Occupations, 50% of 11,546,880 workers receive less than $9.10/hr, and 75% receive less than $11.11/hr. Thus, somewhere around 62.5% of these workers, or about 5.75 million people would receive a higher wage.
- In Sales and Related Occupations, 25% of 13,835,090 workers receive less than $9.12/hr, and 50% receive less than $12.08/hr. So, conservatively, about 3.5 million people would receive a higher wage.
- In Transportation and Material Moving Occupations, 25% of 8,771,690 workers receive less than $10.06/hr. Thus, over 2.1 million people would receive a higher wage.
- In Healthcare Support Occupations, 25% of 3,915,460 workers receive less than $10.03/hr. That’s nearly a million people who would receive a higher wage.
- Overall, 10% of all workers (across all industries) receive an hourly wage lower than $8.70/hr, and 25% of all workers receive an hourly wage lower than $10.81/hr. A rough estimate, then, is that at least one out of every six workers would receive a higher hourly wage if the federal minimum wage were raised to $10.10/hr. To put that in absolute terms:
Over 21,500,000 Americans would receive a higher wage.
…or, about 6 times as many as Dorfman implied.
With that, I leave you with this.
___________________
[1] I will not address the second part of Dorfman’s piece about productivity shifts in the food service industry, and the “ironic” aspect of the mistakes in the piece is the conclusion of the first paragraph, where Dorfman informs the reader that “much of what you hear about the minimum wage is completely untrue.”
[2] I am setting aside the question of how many people who currently earn less than minimum wage would be affected by an increase in the level of the wage. This is a complicated matter for a variety of reasons.
[3] I, like Dorfman, will leave aside the question of overall impact of a minimum wage hike on employment. I am not advocating for or against a minimum wage hike—rather, I am advocating against those who argue that very few workers make very low wages.
___________________
BLS Data:
| Occupation (SOC code) |
Employment(1) |
Hourly mean wage |
Hourly 10th percentile wage |
Hourly 25th percentile wage |
Hourly median wage |
Hourly 75th percentile wage |
Hourly 90th percentile wage |
Annual 10th percentile wage(2) |
Annual 25th percentile wage(2) |
Annual median wage(2) |
| All Occupations(000000) |
130287700 |
22.01 |
8.70 |
10.81 |
16.71 |
27.02 |
41.74 |
18090 |
22480 |
34750 |
| Management Occupations(110000) |
6390430 |
52.20 |
22.12 |
31.56 |
45.15 |
65.20 |
(5)- |
46000 |
65650 |
93910 |
| Business and Financial Operations Occupations(130000) |
6419370 |
33.44 |
16.88 |
22.28 |
30.05 |
40.61 |
53.50 |
35110 |
46340 |
62500 |
| Computer and Mathematical Occupations(150000) |
3578220 |
38.55 |
19.39 |
26.55 |
36.67 |
48.40 |
60.55 |
40330 |
55220 |
76270 |
| Architecture and Engineering Occupations(170000) |
2356530 |
37.98 |
19.45 |
26.16 |
35.35 |
46.81 |
59.52 |
40450 |
54420 |
73540 |
| Life, Physical, and Social Science Occupations(190000) |
1104100 |
32.87 |
15.06 |
20.35 |
28.89 |
41.18 |
55.38 |
31320 |
42330 |
60100 |
| Community and Social Service Occupations(210000) |
1882080 |
21.27 |
11.21 |
14.57 |
19.42 |
26.52 |
34.36 |
23310 |
30310 |
40400 |
| Legal Occupations(230000) |
1023020 |
47.39 |
16.80 |
23.15 |
36.19 |
62.57 |
(5)- |
34940 |
48150 |
75270 |
| Education, Training, and Library Occupations(250000) |
8374910 |
24.62 |
9.94 |
14.66 |
22.13 |
30.85 |
41.54 |
20670 |
30490 |
46020 |
| Arts, Design, Entertainment, Sports, and Media Occupations(270000) |
1750130 |
26.20 |
9.42 |
13.76 |
21.12 |
32.16 |
46.12 |
19600 |
28630 |
43930 |
| Healthcare Practitioners and Technical Occupations(290000) |
7649930 |
35.35 |
14.84 |
20.56 |
28.94 |
40.69 |
61.54 |
30870 |
42760 |
60200 |
| Healthcare Support Occupations(310000) |
3915460 |
13.36 |
8.62 |
10.03 |
12.28 |
15.64 |
19.51 |
17920 |
20850 |
25550 |
| Protective Service Occupations(330000) |
3207790 |
20.70 |
9.09 |
11.71 |
17.60 |
26.89 |
37.35 |
18910 |
24370 |
36620 |
| Food Preparation and Serving Related Occupations(350000) |
11546880 |
10.28 |
7.84 |
8.38 |
9.10 |
11.11 |
14.60 |
16310 |
17430 |
18930 |
| Building and Grounds Cleaning and Maintenance Occupations(370000) |
4246260 |
12.34 |
8.12 |
8.95 |
10.91 |
14.44 |
18.93 |
16890 |
18630 |
22690 |
| Personal Care and Service Occupations(390000) |
3810750 |
11.80 |
7.96 |
8.66 |
10.02 |
13.10 |
18.21 |
16560 |
18010 |
20840 |
| Sales and Related Occupations(410000) |
13835090 |
18.26 |
8.25 |
9.12 |
12.08 |
20.88 |
35.60 |
17170 |
18970 |
25120 |
| Office and Administrative Support Occupations(430000) |
21355350 |
16.54 |
9.17 |
11.51 |
15.15 |
20.18 |
26.13 |
19070 |
23940 |
31510 |
| Farming, Fishing, and Forestry Occupations(450000) |
427670 |
11.65 |
8.23 |
8.65 |
9.31 |
12.97 |
18.64 |
17130 |
18000 |
19370 |
| Construction and Extraction Occupations(470000) |
4978290 |
21.61 |
11.15 |
14.37 |
19.29 |
27.19 |
35.61 |
23190 |
29900 |
40120 |
| Installation, Maintenance, and Repair Occupations(490000) |
5069590 |
21.09 |
10.92 |
14.56 |
19.72 |
26.63 |
33.69 |
22720 |
30290 |
41020 |
| Production Occupations(510000) |
8594170 |
16.59 |
9.02 |
11.05 |
14.87 |
20.26 |
27.11 |
18760 |
22990 |
30920 |
| Transportation and Material Moving Occupations(530000) |
8771690 |
16.15 |
8.56 |
10.06 |
13.92 |
19.41 |
26.83 |
17800 |
20930 |
28960 |
Footnotes:
(1) Estimates for detailed occupations do not sum to the totals because the totals include occupations not shown separately. Estimates do not include self-employed workers.
(2) Annual wages have been calculated by multiplying the hourly mean wage by 2,080 hours; where an hourly mean wage is not published, the annual wage has been directly calculated from the reported survey data.
(5) This wage is equal to or greater than $90.00 per hour or $187,199 per year. |
| SOC code: Standard Occupational Classification code — see http://www.bls.gov/soc/home.htm
Data extracted on January 30, 2014
|
Like this:
Like Loading...


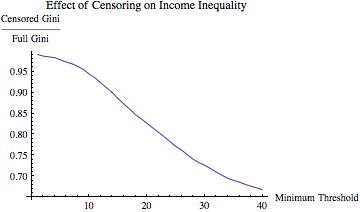
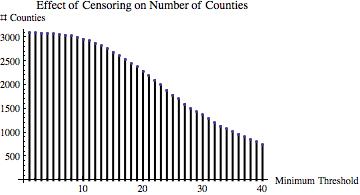
 =1.35) distribution. This pseudo-data yielded a Gini coefficient of
=1.35) distribution. This pseudo-data yielded a Gini coefficient of  . Then I truncated the distribution at various values of m
. Then I truncated the distribution at various values of m and computed the ratio of the Gini coefficient of the resulting truncated data set and the Gini coefficient of the full data set. If decreasing m “should” decrease inequality, then this ratio should be increasing in m.
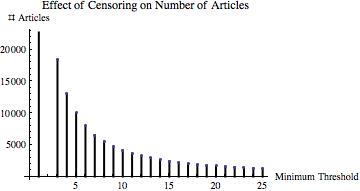
and computed the ratio of the Gini coefficient of the resulting truncated data set and the Gini coefficient of the full data set. If decreasing m “should” decrease inequality, then this ratio should be increasing in m.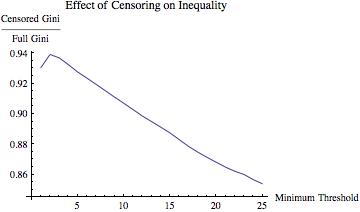
 ,
,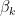 essentially measures the linear impact of variable
essentially measures the linear impact of variable 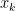 on the outcome variable,
on the outcome variable,  . (The function
. (The function 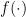 captures nonlinearities, particular for situations in which
captures nonlinearities, particular for situations in which  ,
,  is equal to 0, the conclusion is that there is little or no evidence that
is equal to 0, the conclusion is that there is little or no evidence that  affects
affects 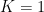 , to focus the discussion. Then, suppose that
, to focus the discussion. Then, suppose that  represents a policy controlled/set by political actors. Now, suppose that political actors are responsive to voter demands, so that they set
represents a policy controlled/set by political actors. Now, suppose that political actors are responsive to voter demands, so that they set  so as to maximize
so as to maximize  . In general, $f$ is a strictly increasing function, so that
. In general, $f$ is a strictly increasing function, so that  implies that
implies that  .
. , isn’t it arguably better to conclude that the marginal effect of
, isn’t it arguably better to conclude that the marginal effect of 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}